Screen Scrape is the process of automatically collecting and extracting data from the visible output of software applications—usually web pages, command-line apps, or legacy terminal systems.
Instead of accessing structured backend data (like through an API or database), screen scraping works with what the user sees on their screen. That might mean reading HTML from a browser window, or text output from an older software interface.
“If an old app won’t give you data, but you can read it—scrape it.”
How Screen Scraping Works in 2025
In its modern form, a screen scrape often behaves like a robotic version of a human. It navigates an app or website, grabs the content, and processes or stores it.
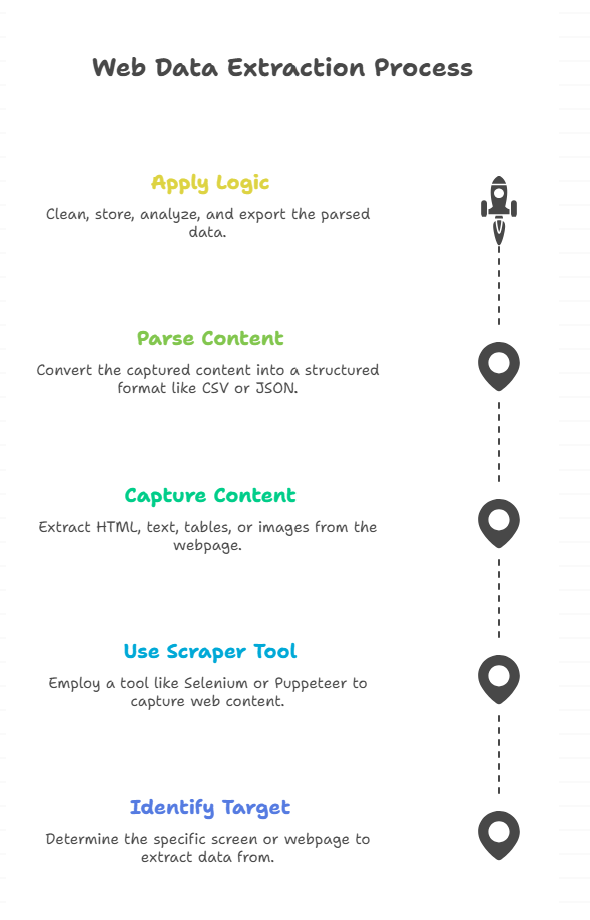
Typical steps:
- Identify the target screen or webpage
- Use a scraper tool (like Selenium, Puppeteer, or Playwright)
- Capture HTML, text, tables, or even images
- Parse the content for structured output (CSV, JSON, SQL, etc.)
- Apply logic: clean, store, analyze, export
In 2025, screen scraping can be enhanced with OCR (optical character recognition), AI-driven selectors, and headless browsing to make extraction faster and more reliable—not to mention stealthier.
Use Cases That Still Justify Screen Scraping
If you’re still asking, “Why not just use an API?”—that’s a fair question.
But there are plenty of real-world data sources that don’t offer APIs, or offer limited, paywalled, or poorly documented ones.
Here are some cases where screen scraping becomes your best (or only) option:
- Legacy internal systems that output terminal-based text
- Old websites with no API but valuable content (think public records)
- Competitor monitoring (pricing, product listings, SEO positions)
- E-commerce intelligence from marketplaces or product comparison sites
- Content aggregation of job listings, reviews, or real estate
And let’s not forget sentiment analysis, legal filings, and academic data—all fair game with the right approach.
Real-World Example: Screen Scraping for Academic Research
One PhD student recently shared on Reddit:
“I had to gather data from 40+ university web portals for a study. No APIs. Manually copying? Impossible. I used a Python scrape webpage script with BeautifulSoup and headless Chrome—it’s what saved my thesis.”
In academia, screen scraping bridges a vital gap between open data and usable data.
The Tools: Scraper Tool Options You Need to Know in 2025
Today’s scraper tools pack more power, stealth, and intelligence than ever. Let’s explore the top ones developers (and non-devs) are using.
Puppeteer (Chrome-based)
Handles dynamic pages rendered by JavaScript. Headless-compatible and great for user simulation.
Playwright (Microsoft)
More modern and stable than Puppeteer. Multi-browser support (Chrome, Firefox, Safari). Easier testing and automation.
Selenium
Classic and open-source. Has been used for web scraping for over a decade. Still works well, now AI-friendly.
BeautifulSoup (for Python scrape webpage tasks)
Excellent for HTML parsing and cleaning content. Lightweight and easy to learn.
Skraper
A specialized screen scraper tool built for downloading metadata, primarily used in gaming/emulation circles—but increasingly valuable for acquiring structured metadata from visual interfaces.
Octoparse
A no-code drag-and-drop UI scraper. Ideal for marketers, researchers, and hobbyists who don’t want to touch code.
What About “List Rawlsr”? (And Other Advanced Scraping Workflows)
You might’ve stumbled upon terms like list rawlsr—a niche tool used in parsing scraped lists line-by-line from rendered screens or structured JSON data.
In advanced workflows, raw list parsing tools like Rawlsr or output stream processors are used to:
- Chunk large scrape outputs into manageable list sections
- Clean and deduplicate big data
- Feed real-time info into databases or dashboards
These mini-frameworks are popular in media monitoring and SEO operations that demand near-real-time updates.
Building a Python Screen Scrape Script (2025 Edition)
If you’re just starting, here’s a simplified structure for a modern Python scrape webpage example using Playwright:
Pythonfrom playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://example.com")
content = page.content()
soup = BeautifulSoup(content, "html.parser")
for item in soup.select(".post-title"):
print(item.get_text())
browser.close()
This combo of Playwright and BeautifulSoup gets you full JavaScript-rendered pages plus an easy parser for structured output.
Ethical and Legal Considerations of Screen Scraping
Of course, with great scraping power comes great responsibility.
Do’s:
- Respect robots.txt guidelines
- Use polite scraping speeds (no flooding servers)
- Attribute and cite data sources when appropriate
- Consider using proper headers/user agents
Don’ts:
- Don’t scrape behind logins without permission
- Don’t ignore rate limits or use scraping for exploitation (e.g., scalping, spam)
- Avoid scraping sensitive data like health or financial records
The legal gray area in 2025 is narrowing. Many companies use anti-bot tech, and some even allow scraping via protected APIs. Always check terms of service.
Common Problems When You Screen Scrape (And How to Solve Them)
❗ Problem 1: Page changes break your scraper
✔ Solution: Use flexible selectors, detect layout changes with logic.
❗ Problem 2: Sites block headless browsers
✔ Solution: Rotate user agents, use full browser shells when needed.
❗ Problem 3: Data is within JavaScript
✔ Solution: Use Playwright or Puppeteer to render full DOM before scraping.
❗ Problem 4: CAPTCHA walls
✔ Solution: Use paid CAPTCHA-solving APIs (only where legal) or avoid scraping high-sensitivity endpoints.
FAQs
Q What is screen scraping used for?
A. Screen scraping is used to extract visible data from applications or websites when APIs or database access isn’t available. It’s helpful in automation, research, data mining, and legacy system integration.
Q Is screen scraping legal?
A. Screen scraping is legal in many cases, especially for publicly available data, but legality depends on how, what, and where you scrape. Always read the website’s terms and robots.txt.
Q What’s the difference between scraping and crawling?
A. Crawling refers to discovering URLs and content (like search engine bots), while scraping is about extracting specific content from those pages. Crawlers index; scrapers collect.
Q Can I screen scrape with Python?
A. Yes! Python is one of the most popular languages for scraping. With libraries like Requests, BeautifulSoup, Playwright, and Scrapy, devs can build powerful workflows in 2025.
Final Thoughts
Despite being around for decades, screen scrape is far from obsolete. In fact, with better data tools, modern scripting languages, and clear ethical guidelines, screen scraping today is more impactful, accessible, and stealthy than ever.
CLICK HERE FOR MORE BLOG POSTS
There’s a certain weight in the words John Authers writes—not just because of what he knows, but how he shares it. His voice doesn’t just echo facts; it builds meaning. In a world overwhelmed by rushed opinions and robotic summaries, John’s writing feels… different. It feels lived-in, thoughtful, and deeply human.
Readers don’t turn to John for headlines—they come for context. They come for that rare blend of clarity, insight, and emotional depth that turns financial journalism into something closer to storytelling. His reflections on markets, geopolitics, or human behavior aren’t just readable—they’re relatable.
What sets John apart isn’t just his experience (though he has plenty of it). It’s his ability to pause, reflect, and explain the why behind the what. He writes like someone who’s been in the room where it happens—but never forgets the reader who hasn’t.
In 2025, when AI churns out articles in milliseconds, John Authers still writes like a human—and that, more than anything, is what makes his work worth reading.